Kernel Exploitation Part Two
This is the secound part of my notes from the lecture about kernel exploitation of pwn.college[0]. Read here about first part.
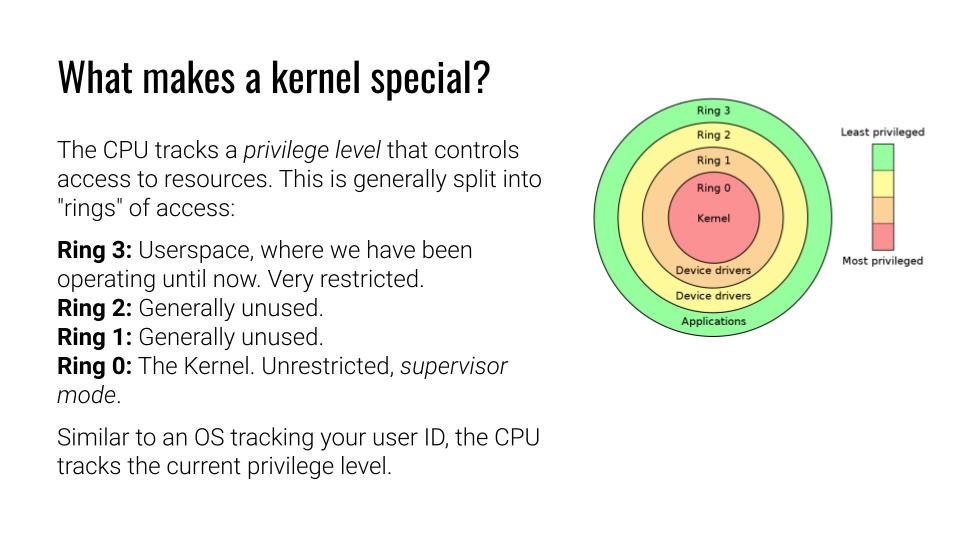
He is continuing with the typical ring diagram. I love the fact that he talks about other architecture than x86, however, he left out which one. Do these architectures have more rings or different types of architectures for the privilege? Maybe is he thinking of ARM[1] with the fewer level of privileges?
The outer ring is 3. It’s the most restricted one, yet that is sufficient to execute Google Chrome or Counterstrike. Some note on this matter: I’m not sure if this accurately depicts because both interact with the GPU that requires some higher privileges? hm…I think about this point to the device driver as an API for such operations. Ah, I know why: The hardware abstraction causes difficulty for games. Game console this to skip this for the sake of performance, I think.
Back to the lecture. Ring 3 is for Userspace mainly. The remaining rings have some rare use cases. For instance, when operating with the in or out instruction. Meaning for a process that requires limited access to hardware, but nothing else instead. Ring 0 is the Supervisor mode. You can do things that might break your hardware.
Fun fact:
Back in the day, when Intel introduced ACPI. The kernel should take care of the power management of physical hardware, like battery and so on. However, most vendors did a poor job with this. So Intel decided to move this feature into an access level of its own that resided within the hardware. We call this the System Management Mode (SMM)[2] or ring -1. It is there to maintain power management with the BIOS level. With the years, it did grow in its function and is invisible to the operating system.
He does not refer to the existence of such modes yet. Instead, he put the kernel into ring 1 and adds the hypervisor as ring 0. Considering the SSM, a Hypervisor could be introduced between hardware and kernel, making this to the ring -1 and then SSM to ring -2. With the Intel ME, we also have an additional layer onto of that adding up more. That’s most often outside of the kernel and can mostly not influenced by it. But at this stage it just becomes bizarre.

He talks about the 2000er years when the first VMs came onto x86. Another fun fact: IBM’s mainframes had full hardware virtualization a long time before. It was just the time when CPU resources could be shared because there were not that well saturated. Instead, resource separation with isolation arises as a need within the x86 market, leading to the creation of the hypervisor.
I guess he talks about these points for the reason, that some software wasn’t able to handle the translation from bare metal to virtualization correctly. Hence, moving the kernel on level up in a virtual matter for a consistent view for the application while still having the hypervisor doing its duty.
Hypervisors are fun. I should take a look more at them.
so far,
akendo
[0] https://cse466.pwn.college/
[1] https://developer.arm.com/documentation/102412/0100/Privilege-and-Exception-levels
[2] https://de.wikipedia.org/wiki/System_Management_Mode